kcp协议
2020年7月26日 星期天, 发表于 深圳
如果你对本文有任何的建议或者疑问, 可以在 这里给我提 Issues, 谢谢! :)
kcp协议是在Github Trending上看到的一个开源项目,项目地址是 https://github.com/skywind3000/kcp,它的简介是
KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低 30%-40%,且最大延迟降低三倍的传输效果。纯算法实现,并不负责底层协议(如UDP)的收发,需要使用者自己定义下层数据包的发送方式,以 callback的方式提供给 KCP。 连时钟都需要外部传递进来,内部不会有任何一次系统调用。
整个协议只有 ikcp.h, ikcp.c两个源文件,可以方便的集成到用户自己的协议栈中。也许你实现了一个P2P,或者某个基于 UDP的协议,而缺乏一套完善的ARQ可靠协议实现,那么简单的拷贝这两个文件到现有项目中,稍微编写两行代码,即可使用。
个人觉得蛮有意思的,决定学习一下,并且记录一下笔记。在之前先回顾一下TCP协议。
1. TCP 协议
参考wikipedia https://zh.wikipedia.org/wiki/%E4%BC%A0%E8%BE%93%E6%8E%A7%E5%88%B6%E5%8D%8F%E8%AE%AE 的概念:
传输控制协议(英语:Transmission Control Protocol,缩写:TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。在简化的计算机网络OSI模型中,它完成第四层传输层所指定的功能。用户数据报协议(UDP)是同一层内另一个重要的传输协议
TCP协议的内容非常之多,在著名的《TCP-IP 详解卷1:协议》一书有大量的介绍,这篇博文不一一复制,只选取笔者关心的一些部分和机制来聊聊,例如协议格式,拥塞控制等
1.1 TCP协议头
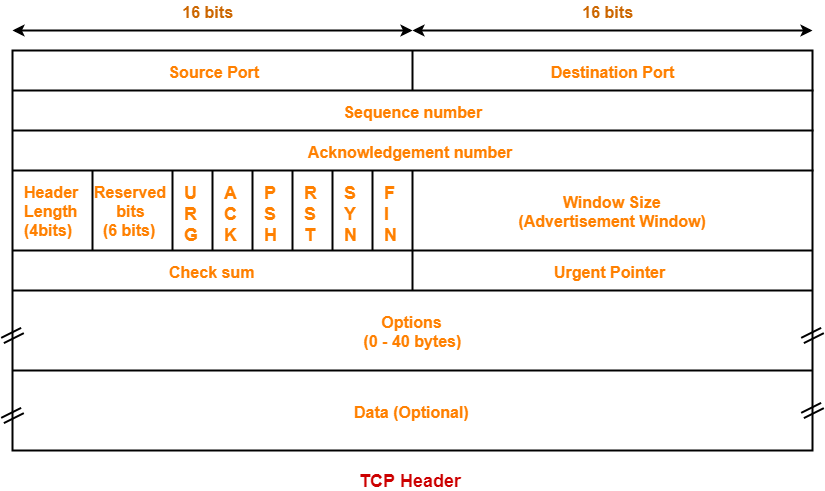
部分字段含义:
| 字段 | 长度bit | 含义 |
|---|---|---|
| Source Port | 16 | 源端口,标识哪个应用程序发送。 |
| Destination Port | 16 | 目的端口,标识哪个应用程序接收。 |
| Sequence Number | 32 | 序号字段。TCP链接中传输的数据流中每个字节都编上一个序号。序号字段的值指的是本报文段所发送的数据的第一个字节的序号。 |
| Acknowledgment Number | 32 | 确认号,是期望收到对方的下一个报文段的数据的第1个字节的序号,即上次已成功接收到的数据字节序号加1。只有ACK标识为1,此字段有效。 |
| URG | 1 | 紧急指针有效标识。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。 |
| ACK | 1 | 确认序号有效标识。只有当ACK=1时确认号字段才有效。当ACK=0时,确认号无效。 |
| PSH | 1 | 标识接收方应该尽快将这个报文段交给应用层。接收到PSH = 1的TCP报文段,应尽快的交付接收应用进程,而不再等待整个缓存都填满了后再向上交付。 |
| RST | 1 | 重建连接标识。当RST=1时,表明TCP连接中出现严重错误(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立连接。 |
| SYN | 1 | 同步序号标识,用来发起一个连接。SYN=1表示这是一个连接请求或连接接收请求。 |
| FIN | 1 | 发端完成发送任务标识。用来释放一个连接。FIN=1表明此报文段的发送端的数据已经发送完毕,并要求释放连接。 |
| Window Size | 16 | 窗口:TCP的流量控制,窗口起始于确认序号字段指明的值,这个值是接收端正期望接收的字节数。窗口最大为65535字节。 |
| Checksum | 16 | 校验字段,包括TCP首部和TCP数据,是一个强制性的字段,一定是由发端计算和存储,并由收端进行验证。在计算检验和时,要在TCP报文段的前面加上12字节的伪首部。 |
| data | 可变 | TCP负载。 |
1.2 TCP可靠传输
可靠传输依靠下面的几个方法协同实现:
- 请求编号:给每一个发送的字节带上编号(可以认为是在一定时间内的幂等ID)
- 接收确认:接收端队对每一个接收到的报文进行确认(实际上是累计确认方式)
- 重传机制:包括快速重传和超时重传
- 校验和机制:
1.2.1 TCP 定时器
对于每一个TCP链接,TCP开启了四种类型的定时器:
- 重传定时器:使用于当希望收到另一端的确认
- 坚持(persist)定时器:使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口
- 保活(keepalive)定时器:可检测到一个空闲连接的另一端何时崩溃或重启
- 2MSL定时器:测量一个连接处于 TIME_WAIT状态的时间
重传定时器简单描述:
客户端向服务端发一个请求数据包,并且同时启动一个定时器,如果在定时器超时之前收到接收端返回的ACK,则认为发送成功,否则任务发送失败,并且触发超时重传。
但是有一个问题是,超时时间设置为多少是合适的?不同的接收方到发送方的距离是不一样的,网络质量也不尽相同,如果设置为相同的超时时间,过长会造成重传效率问题,过短则会造成大量重传,有可能会造成雪崩。
因此我们要根据网络延迟,动态调整超时时间,延迟越大,超时时间越长。
计算重传超时时间的算法可以参考一下这篇博文: https://zhuanlan.zhihu.com/p/101702312
快速重传描述:
如果发送方发送的某个包确实丢失了,例如5,在他发送后面的包6,7,8的时候,接收方会重传对5的ACK,当发送方接收到大量的重复ACK时,就已经知道5这个包丢失了,就可以快速重传
1.3 TCP控制算法
拥塞控制和流量控制是TCP的两个控制算法方式:拥塞控制是对网络整体的保护,避免打爆网络整体;流量控制是滑动窗口限制控制发送方的发送速度,对接收端进行保护
1.3.1 TCP流量控制
TCP流量控制的目的是为了匹配发送速率不一致的接收端和发送端,接收端和发送端各自维护一个发送缓冲区(窗口)和一个接收缓冲区(窗口),接收端会告诉发送端他的接收缓冲区的剩余大小(TCP的header中有一个字段),发送端只需要保证序号空间中未确认的数据量控制在窗口返回值以内即可
1.3.2 TCP拥塞控制
拥塞控制有一点囚徒困境的味道,一般网络如果出现拥塞,表现一般为丢包,此时触发重传,此时如果发送方大量进行重传,则会加重网络的拥塞,造成其他的连接拥塞,甚至陷入死锁。因此TCP使用了一组拥塞控制算法,来控制流量避免整个网络的拥塞。
以下内容主要来自于:
- WIKI: https://en.wikipedia.org/wiki/TCP_congestion_control
- 《TCP-IP 详解卷1:协议》
关键思想是: (个人感觉WIKI的英文描述非常清晰简单)
In TCP, the congestion window is one of the factors that determines the number of bytes that can be sent out at any time. The congestion window is maintained by the sender and is a means of stopping a link between the sender and the receiver from becoming overloaded with too much traffic. This should not to be confused with the sliding window maintained by the receiver which exists to prevent the receiver from becoming overloaded. The congestion window is calculated by estimating how much congestion there is on the link.
When a connection is set up, the congestion window, a value maintained independently at each host, is set to a small multiple of the MSS allowed on that connection. Further variance in the congestion window is dictated by an AIMD approach. This means that if all segments are received and the acknowledgments reach the sender on time, some constant is added to the window size. When the window reaches ssthresh, the congestion window increases linearly at the rate of 1/(congestion window) segment on each new acknowledgement received. The window keeps growing until a timeout occurs. On timeout:
- Congestion window is reset to 1 MSS.
- ssthresh is set to half the congestion window size before the timeout.
- slow start is initiated.
TCP的拥塞窗口是TCP发送端来维护控制网络的拥塞,和TCP的接收窗口不一样。
TCP拥塞控制主要有4类算法:
- 慢启动
- 拥塞避免
- 快速重传
- 快速恢复
具体可以参考这里,这个讲的还蛮有意思的: https://www.cnblogs.com/xiaolincoding/p/12732052.html
先假设,如果让我(你)设计一个拥塞避免算法,应该怎么做?
如果是我,会按照下面的思路来分析
Q: 拥塞避免的目的是什么?
A: 充分利用网络链路,不浪费网络带宽,当拥塞发生时,会有大量的重传包进入网络,造成效率低下,网络利用率低。换言之,拥塞避免就是是实际传输速率尽可能的逼近真实网络带宽
Q: 怎么获得真实的传输速率?
A: 通过反馈机制不断的触探, 不断调高当前发送速率,当出现异常时,认为当前速率高于实际网络传输速度,适当降低传输速度,否则调高传输速度,最终使得当前发送速度近似等于网络最高传输速度,达到某种动态平衡
Q: 怎样认为发生了异常(网络拥塞)? A: 因为无法知道整个网络的所有信息,一个能想到的方法就是通过是否超时来判断网络是否拥塞, 当发送超时重传了,可能网络出现了拥塞。